

I'm currently running whisper on only the left channel and it seems to be working. I guess it is possible you'll miss some conversation because it is only on the right channel, so if you want to be sure I guess run it twice, once for each side. However, conversation tends to be on both channels so I'm not sure whether it's worth the extra effort.
Post your JAV subtitle files here - JAV Subtitle Repository (JSP)★NOT A SUB REQUEST THREAD★
- Thread starter Eastboyza
- Start date
-
Akiba-Online is sponsored by FileJoker.
FileJoker is a required filehost for all new posts and content replies in the Direct Downloads subforums.
Failure to include FileJoker links for Direct Download posts will result in deletion of your posts or worse.
For more information see this thread.

You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.

Haha ...Maybe the JAV studios have found a way to screw Whisper Subs!?

I
Here is my sub for WAAA-501 after fixing the audio problem.
I used whisper-anime model for this one. As a new model, I'm interested to hear your comments about the result.
Attachments
Thanks for this detailed analysis Mei. The One trade-off with the hallucination clean-up (I'm assuming that you've looked at clean_subs.py) this is a work in progress and I will adjust it piecemeal as ideas come to me. My only slight qualm with the hallucination 'filter' is that during those moments where a hallucination has started but is carrying on over obvious dialog, I half think it would be better to at least have dialog, even wrong dialog, when it is obvious that someone is speaking instead of a blank screen where my script has removed the hallucination. It's probably not really relevant but it is an aspect of the filtering process that I am not happy with. I thought about adding some funny word replacements for my own enjoyment, 'have you had anal?-Do you enjoy a poke up the rump? but since these are primarily for others (Akiba) I have curtailed that inclination. The bottom line with Whisper is with its current fallibility you are relegated to good enough rather than, by jove I think I've got it. Right now I'm working on specific actress subs so , everything from Abe Mikado, Kanna Misaki, Lala Kudou, Airi/Meiri Twins, Nanami Nanase, and a bunch more that I can't remember right now (I"m on my laptop while my PC is hard at work creating subs) in any case the next bunch covers movies by actress, about 2000 titles I think, then I move on to my alphabetical folders which is just a mish-mash of everything and is somewhere in the vicinity of 20K files. This is going to be a very long process so if you discover potential tweaks to either my bat or py files to make them more effective, give me a shout. Thanks Mei.We peobbaly need to take this conversation to another thread so we don't hi-jack the main theme. The work that you're planning to do (and doing) is quite valuable and deserves more attention. I will spend more time on it during the weekend, but I thought of doing a quick exploration into your first set of the subs by running some stats on them. Here are some interesting stats:
(1) Hallucination: Your de-halluicnation seems to have worked quite well for known phrases. There doesn't seem to be too many of those occuring in the majority of the files:
View attachment 3671696
(2) Quality: Looking at the characters per seconds (CPS) metric can give an indication of the quality of the timing, or the sub. That can be one way of measuring the quality of a sub. I'd say anything below 10 and higher than 20 might be not optimal.
View attachment 3671723
(3) Quality: Another metric I looked at was for repetition. One metric can be Type-Token Ratio (TTR). This is a bit difficult metric for JAV (or any porn movie), as the vocabulary is not that vastHowever, one doesn't want the TTR to be too close to 0. That can indicate problems in Whisper output like repetition loop.
View attachment 3671724
These are just dumb stats with no knowledge of the genre, or type of movies. So it must be taken with grain of salt. It would be interesting to run the stats for each separate genre or series to see what are the characteristics.
Just checked the first few lines and it looks a lot better than the translation basic whisper gave me.
I've attached the raw results. Left side only, I didn't bother trying the right channel to see which one got the better results, as whisper takes quite a while to finish on my computer.
I've attached the raw results. Left side only, I didn't bother trying the right channel to see which one got the better results, as whisper takes quite a while to finish on my computer.
Attachments
Wow, that looks really great from a quick glance, but I can't compare this to my own as I don't know how to fix the audio problem.Haha ...
View attachment 3671878
I
Here is my sub for WAAA-501 after fixing the audio problem.
I used whisper-anime model for this one. As a new model, I'm interested to hear your comments about the result.
I'd like to see it with actresses that sometimes talk in a very cutesy way, I'm sure any model trained on anime is able to deal with that much more. Ichika Matsumoto comes to mind (maybe MIAA-846 ?).
Wasn't there some problem with the timecodes on that model, you were able to fix it ? Or is this another one ?
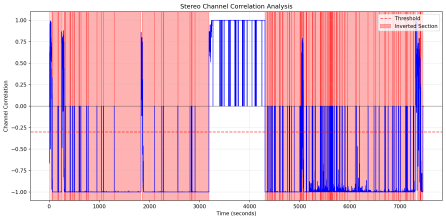
Apparently it's probably "phase cancellation". One of the track has the opposite polarity of the other and they cancel each other out when downmixing to mono. It can be fixed by separating the 2 tracks, inverting one of them(Effect->Special->Invert in audacity) and then merging them back.
For WAAA-501, it looks like one scene in the middle is correct and the rest of the audio is inverted so you'd need to select and invert the 2 bad parts separately(downmix a copy to mono to identify and create labels(ctrl+B) to easily select them after) for 1 track(apparently usually the right one is the problematic one) and then you can get a good full audio for whisper.

Edit: Made a better picture
For WAAA-501, it looks like one scene in the middle is correct and the rest of the audio is inverted so you'd need to select and invert the 2 bad parts separately(downmix a copy to mono to identify and create labels(ctrl+B) to easily select them after) for 1 track(apparently usually the right one is the problematic one) and then you can get a good full audio for whisper.
Edit: Made a better picture
Last edited:
Apparently it's probably "phase cancellation". One of the track has the opposite polarity of the other and they cancel each other out when downmixing to mono. It can be fixed by separating the 2 tracks, inverting one of them(Effect->Special->Invert in audacity) and then merging them back.
For WAAA-501, it looks like one scene in the middle is correct and the rest of the audio is inverted so you'd need to select and invert the 2 bad parts separately(downmix a copy to mono to identify and create labels(ctrl+B) to easily select them after) for 1 track(apparently usually the right one is the problematic one) and then you can get a good full audio for whisper.
View attachment 3671964
Wow, that's a lot trickier than my quick solution. I just did
ffmpeg -i input -af "pan=mono|c0=FL" output
to get the left channel audio only (or FR if you want right only).
I don't have anything more complex to edit audio than ffmpeg so i was the best I could do myself.
I do wish I knew where to get this anime-whisper as it seems to work much better than the regular whisper I have. Or is it one of those versions that you can't run locally but have to upload the file to some server?
worked great, thx !Apparently it's probably "phase cancellation". One of the track has the opposite polarity of the other and they cancel each other out when downmixing to mono. It can be fixed by separating the 2 tracks, inverting one of them(Effect->Special->Invert in audacity) and then merging them back.
For WAAA-501, it looks like one scene in the middle is correct and the rest of the audio is inverted so you'd need to select and invert the 2 bad parts separately(downmix a copy to mono to identify and create labels(ctrl+B) to easily select them after) for 1 track(apparently usually the right one is the problematic one) and then you can get a good full audio for whisper.
View attachment 3671964
Edit: Made a better picture
I tried the python clean up subs thing, seems a bit aggressive on some things ? I might remove some stuff myself.
So i wanted to compare the anime model version vs V2, but I only translated 100 lines and only compared the first 60. I need sleep and can barely keep my eyes open, but really wanted to quickly compare it.
I think I caught like 3 clear mistakes, or audio that didn't get picked up, with the anime one in those 60 lines, but of course it's such a low sample size and even if you transcribe the same audio a second time and do the same parameters and same model, sometimes it will pick up some audio it didn't before.
I'm still very interested in comparing it to an actress that talks in like a really cute voice, I bet if would be better than v2 then.
Attachments
Wasn't there some problem with the timecodes on that model, you were able to fix it ? Or is this another one ?
Yes there still is the problem with timecodes, anime-whisper doesn't return those. My current workaround is to segment the audio around predicted vocals before feeding it to the model. I'm still testing it. I plan to publish it once it is in a beta-level shape.
Hi Sam,Apparently it's probably "phase cancellation". One of the track has the opposite polarity of the other and they cancel each other out when downmixing to mono. It can be fixed by separating the 2 tracks, inverting one of them(Effect->Special->Invert in audacity) and then merging them back.
For WAAA-501, it looks like one scene in the middle is correct and the rest of the audio is inverted so you'd need to select and invert the 2 bad parts separately(downmix a copy to mono to identify and create labels(ctrl+B) to easily select them after) for 1 track(apparently usually the right one is the problematic one) and then you can get a good full audio for whisper.
View attachment 3671964
Edit: Made a better picture
Any thoughts on if this a "one-off" or is this what the future is going to look like in JAVs?
I don't think there's any reason for them to try and prevent subtitles from being made so it's more likely a bad job done by whoever edited it. I've seen some horrible things done on some videos so not everyone know what they're doing even when they are "professionals".
I agree with you here Sam. It seems that someone would deliberately encode audio merely to confuse Whisper like HDCP or DRM it just doesn't make any sense to go to that trouble.I don't think there's any reason for them to try and prevent subtitles from being made so it's more likely a bad job done by whoever edited it. I've seen some horrible things done on some videos so not everyone know what they're doing even when they are "professionals".
If this ever happens again, I wrote (*cough* claude.ai) a script that detects this and corrects it. Didn't even take 10 minutes, seems to work fine when I converted it to mono and listened to it manually. Just skipped through it tho, so it's not 100% tested

Edit : don't use the --plot parameter if you don't have 64GB of ram. I could implement some more memory efficiency, but I doubt anyone would care, just don't use it.
Edit : don't use the --plot parameter if you don't have 64GB of ram. I could implement some more memory efficiency, but I doubt anyone would care, just don't use it.
Attachments
Last edited:
I've been thinking about this and while I agree it would be a lot of trouble to do the first time, but what if you automate it...maybe to protect "your" Chinese Sub makers for the China market. Maybe I've heard too many conspircy theories! lolI agree with you here Sam. It seems that someone would deliberately encode audio merely to confuse Whisper like HDCP or DRM it just doesn't make any sense to go to that trouble.

MILD-934 Capitalize 4 Hour Special Christine

AI translated using DeepSeek v3 0324.
Very roughly manually checked for mistakes and incoherencies.
There's a section from about 2:48:00, where the subs make very little sense. There's shower noise in the background then and, obviously, Whisper had trouble understanding the speech.
I don't speak nor read Japanese so there are certain to be lots of mistakes.
It'd be extra-shiny if mistakes could be pointed out or corrected.
- Code: MILD-934
- Release Date: 2014-09-12
- Director: Bouei Sei
- Studio: K.M.Produce
- Label: Million
- Tags: Restraint, Solowork, Electric Massager, 4HR+, Lotion
- Actress: Aisaka Yuu (Christine Kitajima)
AI translated using DeepSeek v3 0324.
Very roughly manually checked for mistakes and incoherencies.
There's a section from about 2:48:00, where the subs make very little sense. There's shower noise in the background then and, obviously, Whisper had trouble understanding the speech.
I don't speak nor read Japanese so there are certain to be lots of mistakes.
It'd be extra-shiny if mistakes could be pointed out or corrected.
Attachments
ABF-231 Unexpected, Hidden Option Temptation: Reverse Negotiations Hidden In Ordinary Daily Life, Excessive Service From Working Women, Umi Yahagi

AI translated using DeepSeek v3 0324.
Very roughly manually checked for mistakes and incoherencies.
I don't speak nor read Japanese so there are certain to be lots of mistakes.
It'd be extra-shiny if mistakes could be pointed out or corrected.
- Code: ABF-231
- Release date: 2025-06-06
- Category: 1080p, HD, JAV
- Director: Hippagon Katsuya
- Studio: Prestige
- Label: ABF
- Tags: AV Actress, breasts, Cosplay, Facials, Shaved, Solowork
- Series: まさかの、裏オプ誘惑 (Unexpectedly, the temptation of backdoors)
- Actor: Koume, Yuki Yudzuru
- Actress: Yatsugake Umi
AI translated using DeepSeek v3 0324.
Very roughly manually checked for mistakes and incoherencies.
I don't speak nor read Japanese so there are certain to be lots of mistakes.
It'd be extra-shiny if mistakes could be pointed out or corrected.
Attachments
I see there's a lot of smart and high-techy levels guys here, that's amazing!
But finding posted subtitles is really difficult here... Have you ever thought about posting them on https://www.avsubtitles.com and add the link here?
I'm not talking about forum, just talking about hosting the files. So it could be more easy to find. There's already subtitles for +7000 JAV movies, but since it's a fansub site, the quality may vary.
As for me, I don't write subtitles for JAV often, but I'm pretty proud of my work for Akari MITANI's DASS-626. I don't know if it's already posted, but you can find it here: https://www.avsubtitles.com/movie.php?movid=15398
But finding posted subtitles is really difficult here... Have you ever thought about posting them on https://www.avsubtitles.com and add the link here?
I'm not talking about forum, just talking about hosting the files. So it could be more easy to find. There's already subtitles for +7000 JAV movies, but since it's a fansub site, the quality may vary.
As for me, I don't write subtitles for JAV often, but I'm pretty proud of my work for Akari MITANI's DASS-626. I don't know if it's already posted, but you can find it here: https://www.avsubtitles.com/movie.php?movid=15398
SDDE-288 Been bred by the government decide to men while attending, school girls is commonplace to birth country

I downloaded a Sub from AVSubtitles.com as the basis this Sub. I "spiced" it up a bit and I also attempted to clean it up a bit and re-interpreted some of the meaningless/ "lewd-less" dialog. Again, I don't understand Japanese so my re-interpretations might not be totally accurate but I try to match what is happening in the scene. Anyway, enjoy and let me know what you think..
Attachments
Re Subtitles. I would like some feedback please.
My First batch was seperated into categories based on their series name. I processed these because they often had actual dialog.
The next bunch that I am currently working are separated into folders based on actresses that I like here are some of the Actresses which have dedicated folders;
Abe Mikako-154 files, Airi/Meiri Twins-23, Azusa Ayano-71, Ichika Amagai-71, Ichika Nagano-49, Kanna Misaki-145, Lala Kudou-145, Nana Aoyama-61, Nanami Nanasi-20, Riho Yutzuki-23, Rio Hamasaki-142, Sonan-8, Tsubane Hinano-15, Yura Kana-278, Yuri Honma-76, Yuri Koizumi-6. So here is my problem. By seperating the subtitles into these categories it is a bit confusing because, for example, The 154 titles in Abe Mikako folder have tons of other actresses in these titles so it is a bit misleading to say they are only Abe Mikako titles, these are all titles with her in them but someone searching for another actress may miss the file in that specific directory. Also there are videos, like RKI-022, in the Nana Aoyama folder. This video is 16 Hours and has Tons of other actresses. There are also compilation videos but because Abe Mikako has One scene in it that file is listed in her folder. On the other hand there may be a file that is in Kanna Misaki folder that has Abe Mikako in it so someone looking in the Abe Mikako folder may say oh darn it is not there but it may be elsewhere. Yura Kana and Lala Kudo are a perfect example of that. They are in tons of videos together so some may end up in Lala Kudo folder and others in Yura Kana folder. And so, I come to you folks for direction. These actress lists, btw , are only the First batch that I have to process. I have tons more folders that are catalogued according to actress but I am starting to think that my cataloguing system may not translate for this purpose of uploading subtitles for a general audience. I'm starting to think that my next batch should just be everything in these folders without any actress reference. Once I have completed all of the files that I have catalogued this way I will just start doing everything alphabetically. Sorry about the long message. Short and sweet. Continue to sort these subs according to actress or just process them and let people figure out if they're after that subtitle?. I still have a while to go. I figure about a Week more to complete the actresses that I have named here so lots of time for responses. Thanks.
My First batch was seperated into categories based on their series name. I processed these because they often had actual dialog.
The next bunch that I am currently working are separated into folders based on actresses that I like here are some of the Actresses which have dedicated folders;
Abe Mikako-154 files, Airi/Meiri Twins-23, Azusa Ayano-71, Ichika Amagai-71, Ichika Nagano-49, Kanna Misaki-145, Lala Kudou-145, Nana Aoyama-61, Nanami Nanasi-20, Riho Yutzuki-23, Rio Hamasaki-142, Sonan-8, Tsubane Hinano-15, Yura Kana-278, Yuri Honma-76, Yuri Koizumi-6. So here is my problem. By seperating the subtitles into these categories it is a bit confusing because, for example, The 154 titles in Abe Mikako folder have tons of other actresses in these titles so it is a bit misleading to say they are only Abe Mikako titles, these are all titles with her in them but someone searching for another actress may miss the file in that specific directory. Also there are videos, like RKI-022, in the Nana Aoyama folder. This video is 16 Hours and has Tons of other actresses. There are also compilation videos but because Abe Mikako has One scene in it that file is listed in her folder. On the other hand there may be a file that is in Kanna Misaki folder that has Abe Mikako in it so someone looking in the Abe Mikako folder may say oh darn it is not there but it may be elsewhere. Yura Kana and Lala Kudo are a perfect example of that. They are in tons of videos together so some may end up in Lala Kudo folder and others in Yura Kana folder. And so, I come to you folks for direction. These actress lists, btw , are only the First batch that I have to process. I have tons more folders that are catalogued according to actress but I am starting to think that my cataloguing system may not translate for this purpose of uploading subtitles for a general audience. I'm starting to think that my next batch should just be everything in these folders without any actress reference. Once I have completed all of the files that I have catalogued this way I will just start doing everything alphabetically. Sorry about the long message. Short and sweet. Continue to sort these subs according to actress or just process them and let people figure out if they're after that subtitle?. I still have a while to go. I figure about a Week more to complete the actresses that I have named here so lots of time for responses. Thanks.
Re Subtitles. I would like some feedback please.
... I am currently working are separated into folders based on actresses that I like here are some of the Actresses which have dedicated folders;
Abe Mikako-154 files, Airi/Meiri Twins-23, Azusa Ayano-71, Ichika Amagai-71, Ichika Nagano-49, Kanna Misaki-145, Lala Kudou-145, Nana Aoyama-61, Nanami Nanasi-20, Riho Yutzuki-23, Rio Hamasaki-142, Sonan-8, Tsubane Hinano-15, Yura Kana-278, Yuri Honma-76, Yuri Koizumi-6. So here is my problem.
By separating the subtitles into these categories it is a bit confusing because, for example, The 154 titles in Abe Mikako folder have tons of other actresses in these titles so it is a bit misleading to say they are only Abe Mikako titles, these are all titles with her in them but someone searching for another actress may miss the file in that specific directory.
Earlier there was available FREE the Japanese native movies/actresses good source - SOKMIL.COM.
Now this portal is limited/for registered users only/ - and available for Japanese region only.
One could there enter in search Actress name /i.e. Abe Mikako/ and on left side there was a filter -
Single Work / Multiple Performers.
When chosing >
Single Work, one could find particular actress Single Work/ Solowork/ movies only, in descending time order.
Nowadays there are other sources where one could find Single Works movies only -
per example when searching Genres List on portal - Nutjav.com > there is a genre/tag Single Works -
about 13 000 (solowork, only one leading actress) movies, but not possible sort them by actress name.
Or by Gemjav.com > https://gemjav.com/en/genres/single-work
So - to find out actress soloworks - may be there is a point to search particular actress Javlibrary.com page,
and just go through the all movies list. There is the filter by default on > Movies with comments, but
below is available All movies - too.
Abe Mikako > https://www.javlibrary.com/en/vl_star.php?&mode=2&s=azccm - 42 pages /per 20movies on page/
Just to explain - mostly compilation movies (4hrs and longer) are made from shorter excerpts from
longer (2hrs) solowork movies.
Last edited:
Similar threads
- Replies
- 78
- Views
- 65K
- Sticky
- Replies
- 2K
- Views
- 2M
- Replies
- 188
- Views
- 40K
- Replies
- 42
- Views
- 9K
- Replies
- 485
- Views
- 469K