In short: Absolutely, you're spot on – and that's no hallucination (pun intended).
In long: (I started writing this and it ended up way much longer than I wanted

):
Blame it on temperature. What makes Whisper (or any similar AI model) to go wild is the "temperature" parameter. The temperature parameter basically guides how freely the model can make guesses. It can go from conservative (temperature = 0) to wild wild guesses (temperature = 1). The default settings of Whisper is to incrementally increase temperature from 0 to 1 as it processes each audio segment.
Unfortunately many users just use the default settings, which deffinitely is not a good fit for JAV subtitling. That's why you come across wild narratives. A better settings would be to set the temperature to 0 in the parameter settings.
In my experience A balanced combintaion of settings to increase accuracy and to reduce hallucination at the same time would be:
"temperatures": [0.0],
"condition_on_previous_text": False,
"patience": 2,
"beam_size":2,
"hallucination_silence_threshold":1.5,
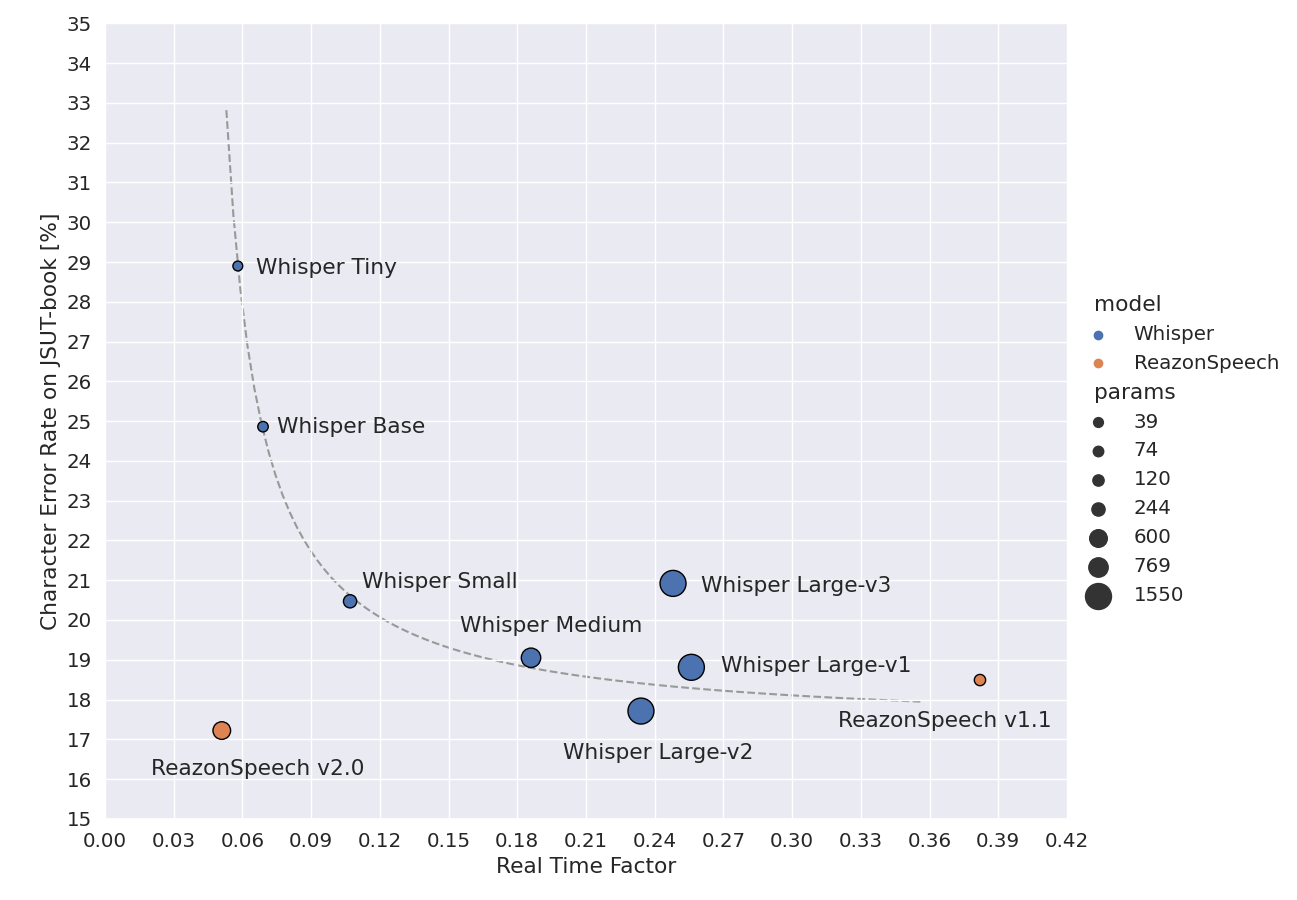
Also I strongly recommend opting for large-v2. Here is a recent benchmark to compare some of the models out there. As many have noticed, large-v3 just sucks. I hope OpenAI releases v4 in couple of months to address the shortcomings of v3.
PS. some people have reported that large-v1 is a better choice for noisy background and cross-talk situations.